Answer scale
Answer scales are instruments provided to respondents to express an answer to a closed-ended question. There are many different ways to create scales, from Likert to semantic differential, to ranks, ratings, and more. In general, answer scales are made of response categories, and the wording and number of categories can influence responses. For this reason, some experts recommend using validated scales. Bruner (2019) is a useful source for validated scales.
Centroid
See Cluster analysis.
Chi squared (χ2)
See Cross tables.
Coefficient of determination
Also known as R squared, the coefficient of determination shown on LogRatio’s histograms measures the portion of the dependent variable that is predicted by the independent variables. It is a measure of fit of the trendline to the original data that varies between zero and one. The larger R squared, the better the fit..
Confidence intervals
Confidence intervals estimate the interval inside which lies the true value of a parameter measured with a sample.
Confidence intervals are created according to a given confidence level, hence the probability of occurrence of the measured parameter.
LogRatio uses the 95% confidence level to construct confidence intervals as follows:
![]()
Where:
- x = Estimated parameter (like a percentage of a cross table)
- Z = Z-score, equal to the number of standard deviations around the parameter, in this case 95% equals a standard score of 1.96.
- p = Hypothesis of the research as entered by the user in field “Population proportion” of the LogRatio form, 0.5 by default
- n = Sample size
Say 54.7% of 320 respondents do not have pets at home. The error level is 5.5%. The confidence interval inside which the true value lies turns out to be 54.7% ±5.5%, or any value in the range 49.2% – 60.2%.
Confidence intervals help in reading the values of survey studies correctly.
The statistical significance can be seen when constructing the confidence interval of the two values. At the 95% confidence level, the confidence intervals are constructed as follows:
Distribution
See Box-plots.
Euclidean Distance
See Cluster analysis.
Exploratory Data Analysis (EDA)
The primary aim of Exploratory data analysis (EDA) is to examine the data for distribution, outliers and anomalies in order to make and test hypotheses. LogRatio applies EDA to assess the quality of the data without making any a priori assumptions.
Herfindahl index (HHI)
The Herfindahl index (also known as Herfindahl–Hirschman Index, HHI, or HHI-score) is a measure of the size of firms in relation to the industry, and is an indicator of the amount of competition among them. It can range from 0 to 1.0, moving from a huge number of small firms to a single monopolistic producer.
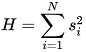
LogRatio adapted HHI to measure the size of an answer class of a question in relation to all other classes of the same question. We call it Index of Concentration.
Likert’s scale
The Likert’s scale is a popular instrument to collect respondent answers to closed-ended questions. It is typically made of 5 or 7 answer classes, although other combinations are also common. The usual 5-point Likert’s scale has a neutral mid-point and two specular extremities. For instance, to ask for the level of agreement with a statement, the following Likert’s scale could be used: “Strongly agree”, “Agree”, “Neither agree nor disagree”, “Disagree”, “Completely disagree”.
See Bruner (2019) for a deeper understanding of answer scales.
Index of Concentration
See Herfindahl index.
Marginal tables
A marginal table, aka marginal tabulation, shows how frequently each answer option of a single question was selected by respondents. They are simply the Sum columns of the cross tables LogRatio makes.
Outlier
LogRatio defines outliers as items of a series lying outside the two standard deviations from the mean. In cases of heavily skewed series, LogRatio may replace the mean with the median value.
Rank-ordered answer scales
LogRatio recognizes two main categories of scales of measurement: Nominal and Ordinal. Nominal scales cannot be ordered by magnitude, for instance: Male, Female, Other gender. On the other hand, ordinal scales can be ordered, for instance: Likely, Neither likely nor unlikely, Unlikely.
Answer scales that can be ordered allow creating indexes and measuring distances between items of the same scale, which is a desirable feature, for instance, when measuring satisfaction using a Customer Satisfaction Index.
There are two more official scales: Interval and Ratio. In LogRatio terms, the Interval scale is part of the Ordinal one, with the difference that the intervals of the former scale are equally spaced.
Simulation model
Simulation models imitate real-life uncertain behaviors, for instance the sales uptake of a new brand. Repeating the model a large number of times, each time changing input parameters, and summarizing appropriately the results of the simulation, produces information useful for reducing the uncertainty or risk associated with the model.
Standard deviation
The standard deviation (sigma, σ) is a measure of dispersion around the mean of a series of numerical data. It is widely used in marketing research, and in the field of analytics in general, to create confidence intervals, thresholds, limits, and the like.
Understanding how the standard deviation works is a necessary requirement to the correct understanding of any advanced analytic technique.
Trendline
The Histograms LogRatio creates in the Descriptive Statistics sheet of the Excel report come with a trendline whose function is that of visualizing the overall shape of the distribution of the respondent answers.
Excel does a great job at adding trendlines to charts. LogRatio adds a polynomial trendline of order three, which means that it uses the time (1, 2, 3, …, n), the time squared, and the time raised to the third power as the independent variables on which to regress the dependent series and estimate the trendline function.
The value R squared, aka coefficient of determination, shown on LogRatio’s histograms measures the portion of the dependent variable that is predicted by the independent variables. It is a measure of fit of the trendline to the original data that varies between zero and one. The larger R squared, the better the fit.